

Exploring Personalized Shopping Experiences with Qdrant's Discovery API
Improve personalized product discovery with Qdrant's Discovery API on a Streamlit web app



Introduction
In the rapidly growing e-commerce landscape, delivering personalized shopping experiences has become one of the key differentiators for success. In this article, we dive deep into the functionality of Qdrant’s new Discovery API, mainly focusing on context search, to unlock tailored product recommendations. To demonstrate this new approach, I’ll walk you through an implementation of a Streamlit App that I have developed, seamlessly integrating with Qdrant’s vector database.
Trust me, it’s fun! ✌️
Discovery API
Qdrant’s Discovery API introduces the concept of “context,” which is a powerful tool for splitting the vector space efficiently, where the context comprises positive-negative pairs, effectively dividing the space into sub-zones based on given user preferences. The search mechanism in this context gives priority to points that actually belong to the positive zones while avoiding the negative ones.
There are mainly 2 types of search:
1. Discovery Search: Utilizes target and context pairs to find points that are closest to the target but constrained by the provided context pair. This is ideal for combining multimodal, vector-constrained searches.
2. Context Search: Uses only the context pairs to identify points residing in the best zone possible while minimizing loss. Particularly effective when a target is absent, guiding the search based on areas with fewer negative examples.
Flexibility
Arrangement of the positive and negative examples in context pairs is quite flexible, offering the freedom to experiment with different permutation techniques based on the model and data. The speed of search is linearly related to the number of examples, providing efficiency in exploring vast datasets.
Environment Setup
- Start the local Docker application on your system and pull the latest Qdrant client container from Docker Hub. Then run the container on port
6333.
NOTE: If you are running on Windows, kindly replace $(pwd) with your local path.
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
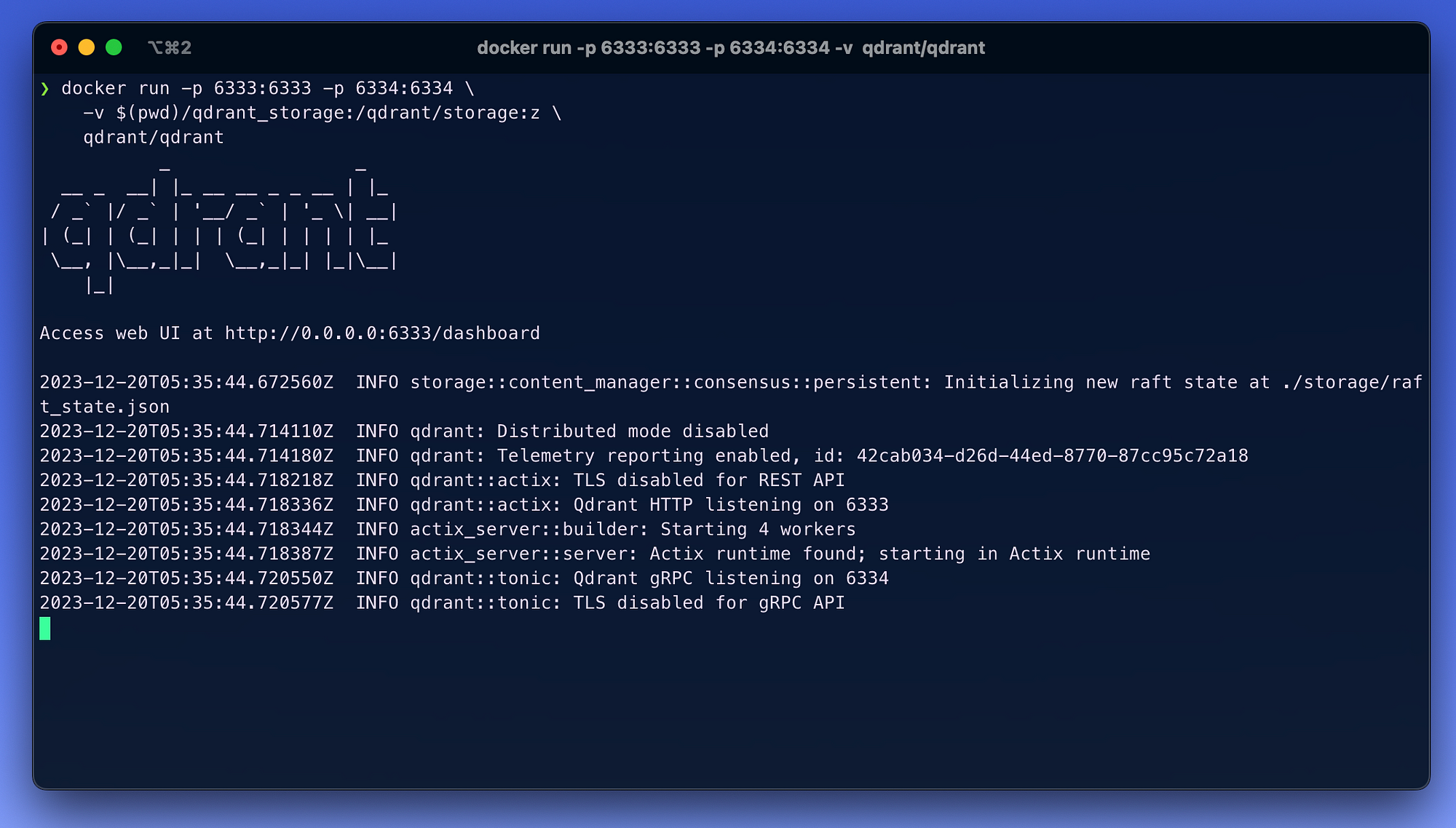
You can also access a beautiful Qdrant server dashboard through
localhost:6333/dashboard, where you can browse through and interact with your data.I always prefer to create a Conda environment for most of my projects. It helps me differentiate between projects well and manage various environments easily.
conda create -n qdrant -y
- Install the necessary dependencies for the project.
pip install qdrant-client sentence-transformers tqdm datasets streamlit
Populating Vector Data Collection
For populating the vector database, we create an “e-shopping” vector data-collection that hosts the vectorized form of our dataset cloned from Hugging Face hub through the datasets library.
- Initialize a Qdrant client instance to communicate with the Qdrant service running on your local machine.
qdrant = QdrantClient("localhost", port=6333)
- Download the desired dataset from the HF library. I have chosen ‘products-2017’ as my sample dataset for demonstration.
dataset = load_dataset("wdc/products-2017", split='train')
- Process the dataset by extracting specific fields (‘title_left’, ‘description_left’) and create a list of dictionaries.
data = []
fields = ['title_left', 'description_left']
for i in tqdm(range(len(dataset)), total=len(dataset)):
if dataset[i]['description_left']:
data.append({field: dataset[i][field] for field in fields})
- To generate embedding vectors of the product description, I am using the all-new “gte-small” encoder model from the GTE collection that is currently trending in the AI community, which is a pre-trained Sentence Transformer model. This model generates a 384-dimensional feature representation for a given input text and is quite fast on inference. If you wish to experiment with bigger models like RoBERTa or DeBERTa, please do; they might fetch better results.
encoder = SentenceTransformer('thenlper/gte-small')
- Create a Qdrant data collection named ‘e-shopping’ with COSINE as the distance metrics.
qdrant.recreate_collection(
collection_name="e-shopping",
vectors_config=models.VectorParams( size=encoder.get_sentence_embedding_dimension(),
distance=models.Distance.COSINE))
- Iterating through the processed data while encoding text descriptions and uploading vectors along with associated data to the newly created Qdrant collection.
records = []
for idx, sample in tqdm(enumerate(data), total=len(data)):
if sample['description_left']:
records.append(models.Record( id=idx, vector=encoder.encode(sample["description_left"]).tolist(),
payload=sample))
qdrant.upload_records(collection_name="e-shopping", records=records)
NOTE: Complete code snippet is given at the end
Streamlit App
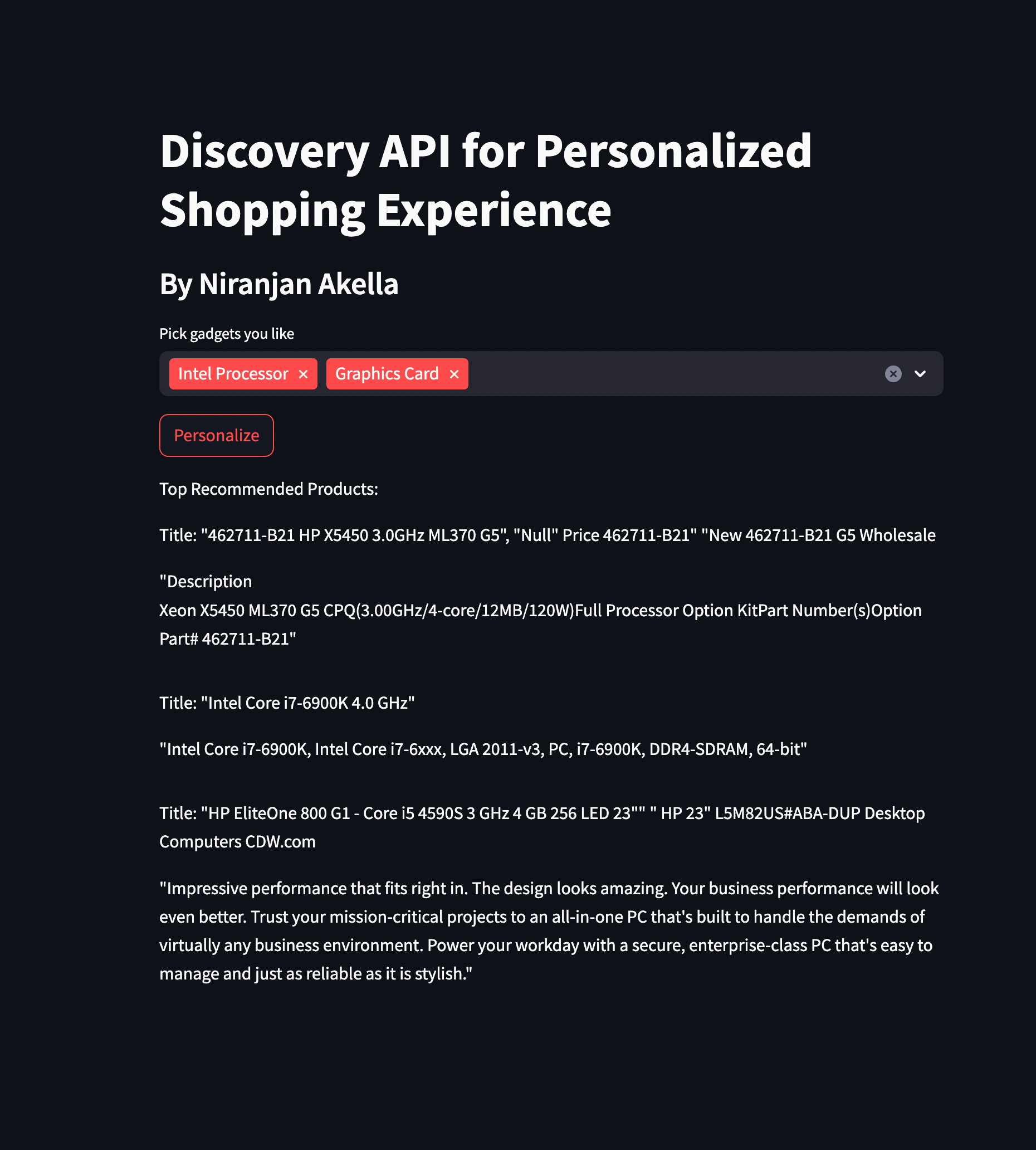
Running the experiment on Streamlit
- Streamlit is one of my favorites when it comes to quick prototyping of ideas. In this app, users can select their preferred gadgets and receive personalized recommendations utilizing Qdrant’s Discovery API.
Let’s quickly walk through the app development.
- Initialize the Qdrant client, establish a link to the local docker container, and load the ‘gte-small’ transformer model for generating the embedding for the desired context.
qdrant = QdrantClient("localhost", port=6333)
encoder = SentenceTransformer('thenlper/gte-small')
- Then we simply create a quick multi-select to allow the end-user to choose their preferred gadgets. Subsequently, we conduct a discovery search, taking into account the provided positive selections and contrasting them with negative choices made by the end-user. We integrate these choices and load them as context pairs. This enables us to uncover the top three recommendations through the Discovery API.
def main():
st.title("Discovery API for Personalized Shopping Experience")
st.subheader("By Niranjan Akella")
# Multi-select checkbox for the first category
choice_of_gadget = st.multiselect(
"Pick gadgets you like",
Gadget,
default=["Intel Processor", "Graphics Card"],
key="category1"
)
disliked_gadgets = list(set(Gadget) - set(choice_of_gadget))
# "Personalize" button to trigger a function
if st.button("Personalize"):
personalize_function(choice_of_gadget, disliked_gadgets)
def personalize_function(choice_of_gadget, disliked_gadgets):
contexts = [models.ContextExamplePair(positive=encoder.encode(l).tolist(), negative=encoder.encode(d).tolist()) for (l, d) in list(zip(choice_of_gadget, disliked_gadgets))]
discovered_products = qdrant.discover(collection_name='e-shopping', context=contexts, limit=3)
st.write("Top Recommended Products:")
for product in discovered_products:
st.write(f"Title: {product.payload['title_left']}")
st.write(product.payload['description_left'])
st.write("\n")
Sample Discovered Choices Based on User Preferences:
User choice: [Intel Processor, Graphics Card]
Top recommended products with a discovery limit of 2 on Streamlit:
“Intel Core i7–6900K 4.0 GHz: Intel Core i7–6900K, Intel Core i7–6xxx, LGA 2011-v3, PC, i7–6900K, DDR4-SDRAM, 64-bit”
“AJA Kona 4 — video capture adapter PCIe 2.0 x8” “ AJA x8 KONA Design Graphic/Video Cards CDWG.com”
Conclusion
Qdrant’s new Discovery API opens up novel possibilities for creating personalized shopping experiences. You can seamlessly integrate it into your applications to offer your end-users a unique tailored experience that goes beyond the basic product recommendations that we generally see. This article covers everything that you need to know about the Discovery API, providing you with proper detailed explanations accompanied by relevant code snippets at every step possible. As an on-field AI/ML engineer, I am positive that Qdrant is the next big thing in handling vector databases and coming up with new approaches in this specific domain.
datasets==2.11.0
qdrant-client==1.7.0
sentence_transformers==2.2.2
tqdm==4.65.0
sentencepiece==0.1.99
transformers==4.36.2
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from qdrant_client import models, QdrantClient
from tqdm import tqdm
'''
If you face any SSL issues while downloading the dataset or model
uncomment the follwoing to by-pass curl certificate verification
'''
# import os
# os.environ['CURL_CA_BUNDLE'] = ''
#instantiate qdrant client
print("[INFO] Client created...")
qdrant = QdrantClient("localhost", port=6333)
#download dataset from hugging face
print("[INFO] Loading dataset...")
dataset = load_dataset("wdc/products-2017", split='train')
#process dataset
print("[INFO] Processing dataset...")
data = []
fields = ['title_left', 'description_left']
for i in tqdm(range(len(dataset)), total=len(dataset)):
if dataset[i]['description_left']:
data.append({field:dataset[i][field] for field in fields})
#importing the GTE model
print("[INFO] Loading encoder model...")
encoder = SentenceTransformer('thenlper/gte-small')
#creating data collection in qdrant
print("[INFO] Creating a data collection...")
qdrant.recreate_collection(
collection_name="e-shopping",
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(), # Vector size is defined by used model
distance=models.Distance.COSINE,
),
)
#uploading vectors to data collection
print("[INFO] Uploading data to data collection...")
records = []
for idx, sample in tqdm(enumerate(data), total=len(data)):
if sample['description_left']:
records.append(models.Record(
id=idx, vector=encoder.encode(sample["description_left"]).tolist(), payload=sample
) )
qdrant.upload_records(
collection_name="e-shopping",
records=records,
)
print("[INFO] Successfully uploaded data to datacollection!")
import streamlit as st
from sentence_transformers import SentenceTransformer
from qdrant_client import models, QdrantClient
#instantiate qdrant client
print("[INFO] Client created...")
qdrant = QdrantClient("localhost", port=6333)
#importing the GTE model
print("[INFO] Loading encoder model...")
encoder = SentenceTransformer('thenlper/gte-small')
print("[INFO] Running Streamlit Application!! ")
Gadget = ["Apple Macbook", "USB Drive", "Hard Drive",
"Intel Processor", "Memory Card", "Graphics Card"]
def main():
st.title("Discovery API for Personalized Shopping Experience")
st.subheader("By Niranjan Akella")
# multi-select checkbox for gadgets
choice_of_gadget = st.multiselect(
"Pick gadgets you like",
Gadget,
default = ["Intel Processor", "Graphics Card"],
key="category1"
)
disliked_gadgets = list(set(Gadget) - set(choice_of_gadget))
# "Personalize" button to trigger a function
if st.button("Personalize"):
personalize_function(choice_of_gadget, disliked_gadgets)
#personalize fn to perform discovery search
def personalize_function(choice_of_gadget, disliked_gadgets):
#encode choices and group context pairs
contexts = [models.ContextExamplePair(positive=encoder.encode(l).tolist(), negative=encoder.encode(d).tolist()) for (l,d) in list(zip(choice_of_gadget, disliked_gadgets))]
discovered_products = qdrant.discover(collection_name='e-shopping', context=contexts, limit=3)
st.write("Top Recommended Products:")
for product in discovered_products:
st.write(f"Title: {product.payload['title_left']}")
st.write(product.payload['description_left'])
st.write("\n")
if __name__ == "__main__":
main()
You can checkout the complete Git-gist ====> here ≤====
That's a wrap, folks!
Until next time, keep hustling and keep innovating. If you wanna catch up, feel free to reach out on LinkedIn or X